Один из часто задаваемых вопросов о цифровой платформе RITM³ – «какова скорость выполнения расчетов в модуле транспортного планирования и моделирования в сравнении с PTV Visum?». Мы провели соответствующие тесты и делимся результатами.
Сравнение скорости расчетов RITM³ и PTV Visum
Что сравнивали? Скорость расчета процедуры загрузки сети для индивидуального транспорта (ИТ), которая принимает на вход одну или несколько (для каждого сегмента спроса) матриц корреспонденций и равновесно распределяет корреспонденции по путям с выводом результирующей нагрузки на элементах улично-дорожной сети.
Что делали? Провели расчеты с одним сегментом спроса и с фиксированным количеством итераций (100) в быстром варианте без сохранения путей для четырех моделей разного масштаба.
Что сравнивали? Скорость расчета процедуры загрузки сети для индивидуального транспорта (ИТ), которая принимает на вход одну или несколько (для каждого сегмента спроса) матриц корреспонденций и равновесно распределяет корреспонденции по путям с выводом результирующей нагрузки на элементах улично-дорожной сети.
Что делали? Провели расчеты с одним сегментом спроса и с фиксированным количеством итераций (100) в быстром варианте без сохранения путей для четырех моделей разного масштаба.
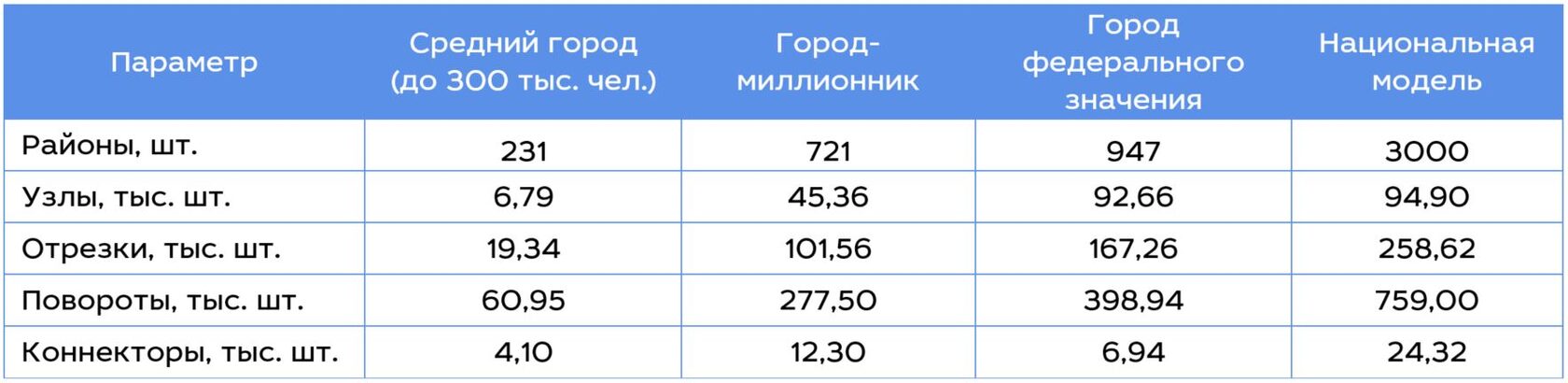
Какие модели использовались для расчета? Параметры транспортных моделей приведены в таблице 1.
Таблица 1. Параметры транспортных моделей
Какую технику использовали? Intel® Core™ i9-7920X с 12 физическими и 24 логическими ядрами с базовой частотой 2.90 GHz под управлением OS Windows 10.
Какие результаты? В таблице 2 приведено сравнение времен описанного выше расчета в RITM³ и двух версиях PTV Visum (18 и 2022):
Какие результаты? В таблице 2 приведено сравнение времен описанного выше расчета в RITM³ и двух версиях PTV Visum (18 и 2022):
Таблица 2. Время расчета (сек.)
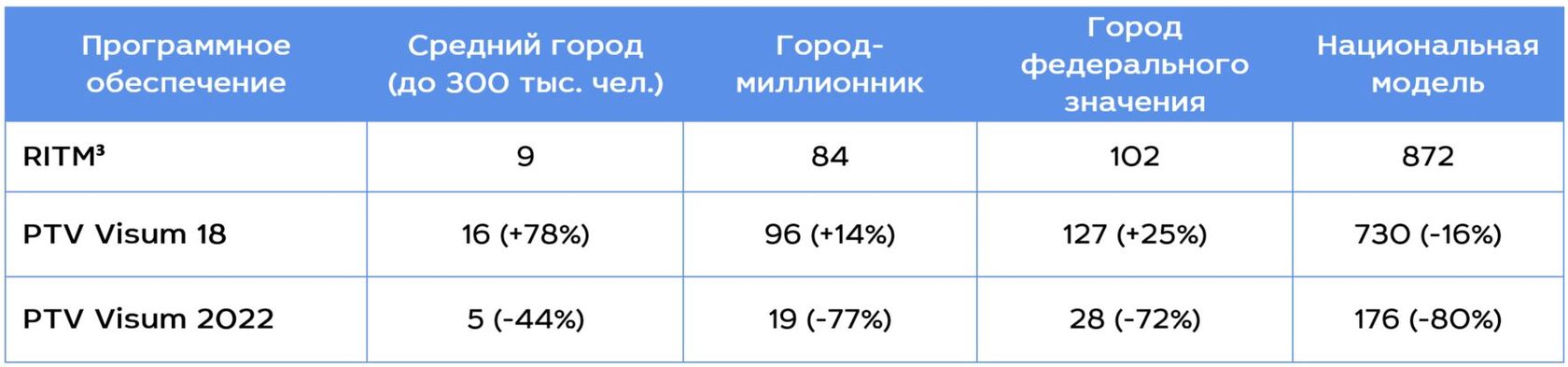
Очень большая разница во времени расчета в PTV Visum версий 18 и 2022 обусловлена изменениями в алгоритмах поиска кратчайших путей. В версии PTV Visum 2022 реализован подход, известный как Customizable Contraction Hierarchies, позволяющий получить существенное ускорение расчета. Аналогичные подходы в RITM³ на текущий момент не используются (однако планируются к реализации в ближайшее время, см. ниже), поэтому более объективным и показательным будет сопоставление с PTV Visum 18, в сравнении с которым RITM³ аналогичный расчет выполняет за сопоставимое время, причем для 3 из 4 тестовых моделей оказывается даже быстрее.
Эффективность параллельной реализации
Во всех ресурсоемких расчетных процедурах RITM³ мы используем параллельные вычисления, что позволяет задействовать все доступные ядра центрального процессора даже при выполнении одного расчета и получать результат в минимальные сроки. Без этого каждый отдельный расчет выполнялся бы на порядок дольше.
Теоретически это можно компенсировать запуском нескольких расчетов разных сценариев одновременно (в соответствии с числом логических ядер процессора), не ускоряя каждый отдельный расчет, но получая результаты всех расчетов за схожее время.
В реальности же в лучшем случае расчет будет выполняться заметно дольше (кэш процессора будет использоваться намного менее эффективно), а в худшем есть вероятность и вовсе столкнуться с нехваткой оперативной памяти для расчета большого числа моделей. Также в эту ситуацию могут вмешаться ограничения лицензии на количество одновременно выполняемых расчетов.
Для анализа эффективности параллельных вычислений мы провели серию расчетов с ограничениями на количество вычислительных потоков и определили коэффициенты ускорения – отношение времен расчета в однопоточном и многопоточном сценарии – в зависимости от числа потоков. Из графика видно, что процедура расчета загрузки сети ИТ в RITM³ более эффективно использует многоядерную архитектуру процессора, чем аналогичная процедура в PTV Visum.
Эффективность параллельной реализации
Во всех ресурсоемких расчетных процедурах RITM³ мы используем параллельные вычисления, что позволяет задействовать все доступные ядра центрального процессора даже при выполнении одного расчета и получать результат в минимальные сроки. Без этого каждый отдельный расчет выполнялся бы на порядок дольше.
Теоретически это можно компенсировать запуском нескольких расчетов разных сценариев одновременно (в соответствии с числом логических ядер процессора), не ускоряя каждый отдельный расчет, но получая результаты всех расчетов за схожее время.
В реальности же в лучшем случае расчет будет выполняться заметно дольше (кэш процессора будет использоваться намного менее эффективно), а в худшем есть вероятность и вовсе столкнуться с нехваткой оперативной памяти для расчета большого числа моделей. Также в эту ситуацию могут вмешаться ограничения лицензии на количество одновременно выполняемых расчетов.
Для анализа эффективности параллельных вычислений мы провели серию расчетов с ограничениями на количество вычислительных потоков и определили коэффициенты ускорения – отношение времен расчета в однопоточном и многопоточном сценарии – в зависимости от числа потоков. Из графика видно, что процедура расчета загрузки сети ИТ в RITM³ более эффективно использует многоядерную архитектуру процессора, чем аналогичная процедура в PTV Visum.
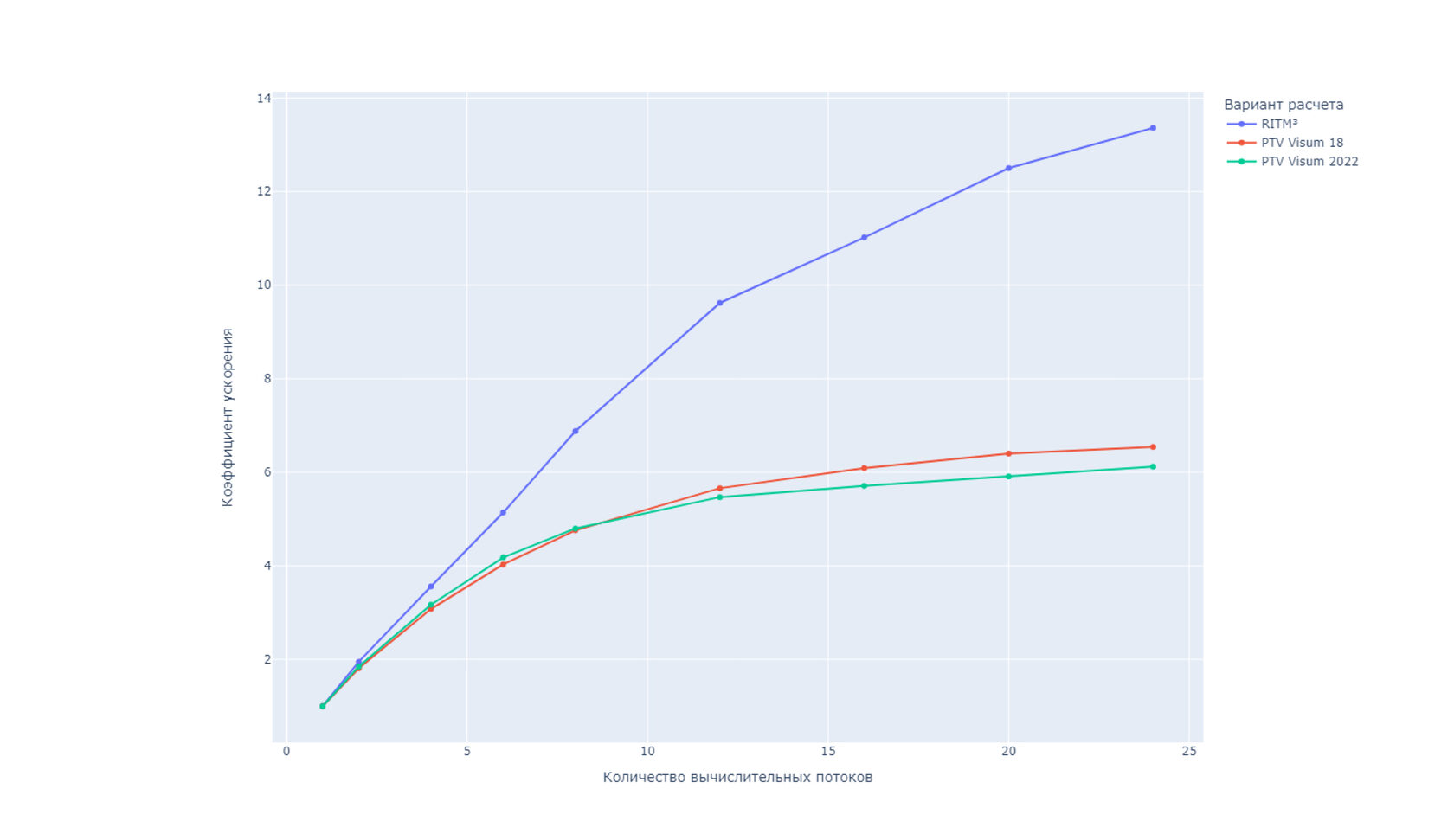
Для пользователей это означает эффективность инвестиций в вычислительную инфраструктуру: приобретая процессоры с большим числом ядер вы получаете более высокий прирост производительности.
Например, увеличение количества логических ядер процессора в 2 раза с 12 до 24 приводит к ускорению расчета в RITM³ на 39%, в то время как в PTV Visum прирост производительности будет значительно ниже – 15% и 12% для версий 18 и 2022 соответственно.
Какие перспективы?
Текущий уровень производительности RITM³ – это далеко не предел, и в следующих версиях скорость расчетов будет увеличена за счет как оптимизации программной реализации, так и внедрения новых алгоритмов расчета, в первую очередь уже упомянутого выше подхода Contraction Hierarchies.
Выводы
Например, увеличение количества логических ядер процессора в 2 раза с 12 до 24 приводит к ускорению расчета в RITM³ на 39%, в то время как в PTV Visum прирост производительности будет значительно ниже – 15% и 12% для версий 18 и 2022 соответственно.
Какие перспективы?
Текущий уровень производительности RITM³ – это далеко не предел, и в следующих версиях скорость расчетов будет увеличена за счет как оптимизации программной реализации, так и внедрения новых алгоритмов расчета, в первую очередь уже упомянутого выше подхода Contraction Hierarchies.
Выводы
- RITM³ уже сейчас демонстрирует сопоставимую с PTV Visum производительность расчетов в ключевых ресурсоемких расчетных процедурах
- RITM³ более эффективно использует многоядерную архитектуру современных процессоров, обеспечивая больший прирост в производительности расчетов при увеличении числа ядер
- RITM³ имеет потенциал дальнейшего повышения производительности расчетов в следующих версиях, который будет обязательно реализован